30 czerwca 2026 Anthropic wypuścił Claude Sonnet 5 i od razu nazwał go najbardziej "agentowym" modelem z linii Sonnet, czyli takim, który sam planuje kroki i kończy zadania bez ciągłego pilnowania. Nikt masowo nie odwołał urlopu, żeby usiąść do testowania nowego modelu (chyba nikt też nie wpadł na odwrotny pomysł i nie poszedł na urlop, żeby uciec przed kolejną premierą AI), więc zanim social media zaleją opinie, warto sprawdzić spokojnie, co ta zmiana oznacza dla firmy, która nie zatrudnia zespołu programistów, tylko chce, żeby AI ogarniało realną robotę.
Z tego artykułu dowiesz się:
- Co faktycznie zmienia się względem Sonnet 4.6 dla firmy, która nie pisze kodu na co dzień
- Ile to kosztuje i jak zmienia się rachunek za AI po 31 sierpnia 2026
- Dla kogo Sonnet 5 robi różnicę, a kto tej zmiany w ogóle nie zauważy
- Czy przełączać istniejące automaty i workflow, czy zostać przy starym modelu
- Co mówią praktycy po pierwszych dniach testów na Reddicie i YouTube
Claude Sonnet 5: co nowy model Anthropic zmienia dla małej firmy
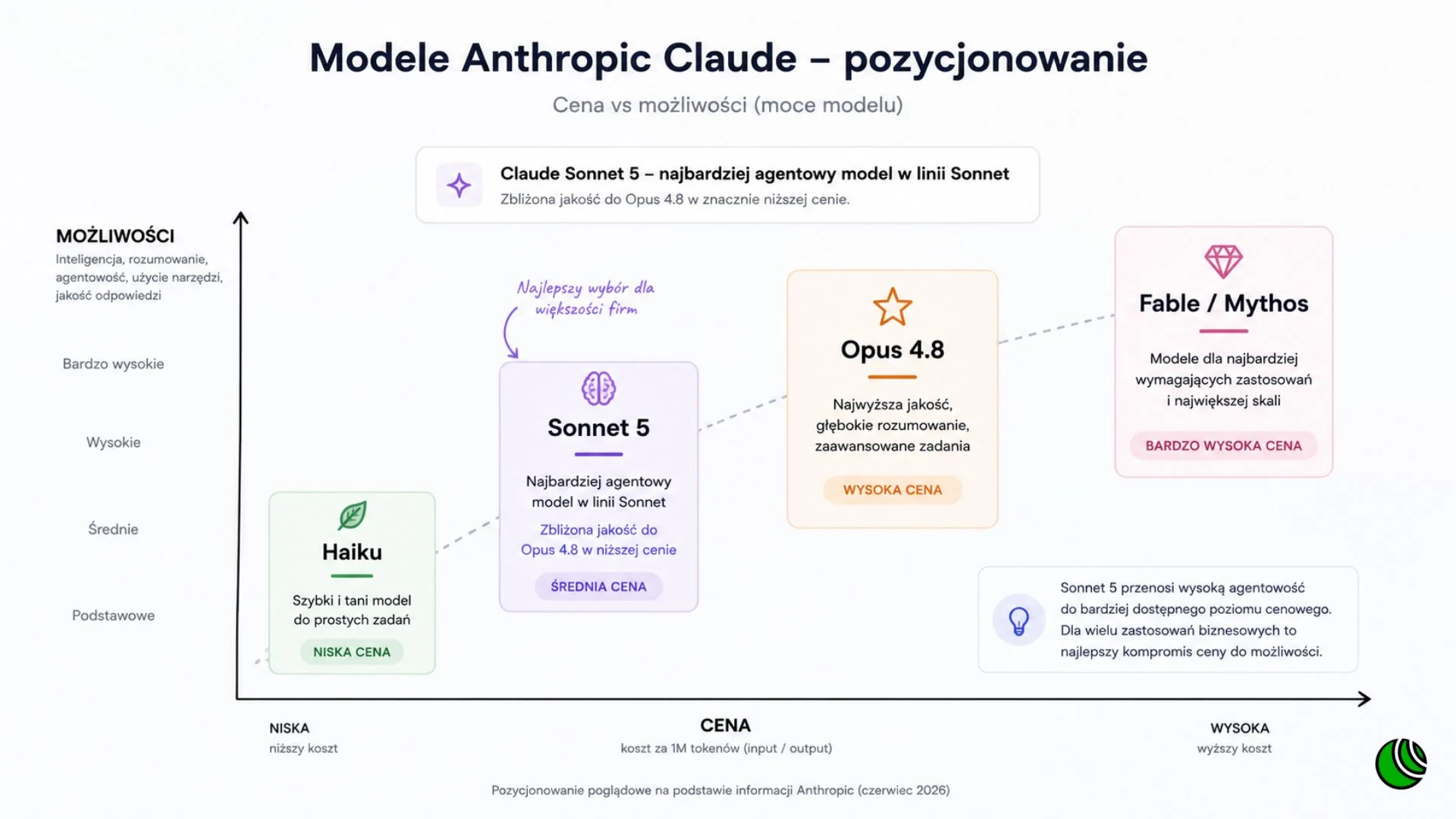
Zanim przejdziemy do konkretów, warto ustawić punkt odniesienia. W linii modeli Anthropic Sonnet to środkowa półka. Poniżej jest tańszy i szybszy Haiku, do prostych zadań. Powyżej Sonneta siedzi droższy i bardziej rozbudowany Opus, a jeszcze wyżej rodzina Fable i Mythos, zarezerwowana dla najbardziej wymagających zastosowań. Sonnet od zawsze był kompromisem: wystarczająco mądry, żeby robić realną robotę, wystarczająco tani, żeby nie bolało przy większej skali.
Ten artykuł, tak przy okazji, powstał przy współpracy z samym Sonnet 5. Model pomógł zebrać materiały źródłowe do tego tekstu, co samo w sobie jest niezłą ilustracją tego, o czym za chwilę będzie mowa.
Co "agentowy" znaczy w praktyce
Anthropic ogłosił Sonnet 5 30 czerwca 2026 roku jako najbardziej agentowy model w historii tej linii. Agentowy w praktyce znaczy tyle, że model nie czeka na kolejne polecenie po każdym kroku. Sam układa plan, sięga po narzędzia takie jak przeglądarka czy terminal, i prowadzi zadanie od początku do końca, zamiast odpowiadać wyłącznie na pojedyncze pytania w oknie czatu.
Konkret od Anthropic: jakość Sonnet 5 zbliża się do droższego Opus 4.8, przy wyraźnie niższej cenie. To zmiana pozycjonowania całej linii. Dawniej wysoki poziom agentowości był zarezerwowany dla najdroższego modelu, teraz schodzi do warstwy średniej. Model jest dostępny we wszystkich planach, a dla kont Free i Pro jest domyślny, więc większość użytkowników zetknie się z nim bez świadomego wyboru.
W recenzji CodeRabbit, autorstwa Juana Pablo Floresa i Gowthama Kishore Vijaya, pojawia się obserwacja, że model potrafi w trakcie zadania przepisać własny plan, gdy okazuje się, że cel się przesunął, zamiast trzymać się sztywno pierwszego pomysłu. Dla firmy bez zespołu technicznego oznacza to mniej sytuacji, w których automatyzacja "utyka w połowie roboty" i wymaga ręcznej interwencji.
Anthropic pokazuje to na przykładzie dwuetapowego zadania: aktualizacja poziomów kont w CRM i wysyłka ogłoszenia do klientów korporacyjnych. Wcześniejsze wersje modelu zatrzymywały się w połowie takiego zadania.
"We handed Claude Sonnet 5 a two-part job, update Salesforce account tiers, send a launch announcement to enterprise contacts, and it finished end to end. That used to stall halfway. For day-to-day automation, it's a no-brainer" mówi Daniel Shepard, Senior Engineer w Zapier.
Druga strona medalu to bezpieczeństwo. Model lepiej odmawia niebezpiecznych próśb i jest bardziej odporny na prompt injection, czyli próby przemycenia złośliwej instrukcji ukrytej w dokumencie albo stronie, którą model przetwarza. Dla firmy puszczającej agentów na dokumenty klientów to konkretna, praktyczna korzyść, nie ciekawostka techniczna.
"Claude Sonnet 5 gets more done with less. Same output quality, fewer steps to get there. It refuses unsafe requests cleanly and consistently, too" mówi Fabian Hedin, Co-founder Lovable.
Uczciwie: to nie jest przełom generacyjny. Testy Anthropic potwierdzają wyraźny krok naprzód w konkretnych obszarach, rozumowaniu, użyciu narzędzi, kodowaniu i pracy z wiedzą, ale nie rewolucję. I dokładnie stąd bierze się notatka, którą warto zapamiętać na dłużej: agent jest wart tyle, ile porządek w danych i procesach, na których pracuje. Na bałaganie nawet najlepszy model niczego nie dowiezie, najwyżej zrobi ten sam bałagan szybciej.
Ile kosztuje Claude Sonnet 5 i jak zmienia rachunek za AI w małej firmie
Zanim ktokolwiek zacznie liczyć oszczędności albo straty, warto rozłożyć mechanikę na czynniki pierwsze. Modele takie jak Sonnet 5 nie mają jednej ceny za "pytanie". Płaci się za tokeny, czyli małe kawałki tekstu, mniej więcej pół słowa każdy. Osobno liczony jest input, czyli to, co wysyłasz do modelu (twój dokument, prompt, dane), i osobno output, czyli to, co model odpowiada. Im dłuższy dokument wrzucasz i im dłuższą odpowiedź model generuje, tym więcej tokenów, tym wyższy rachunek.
Cennik promocyjny, który nie potrwa wiecznie
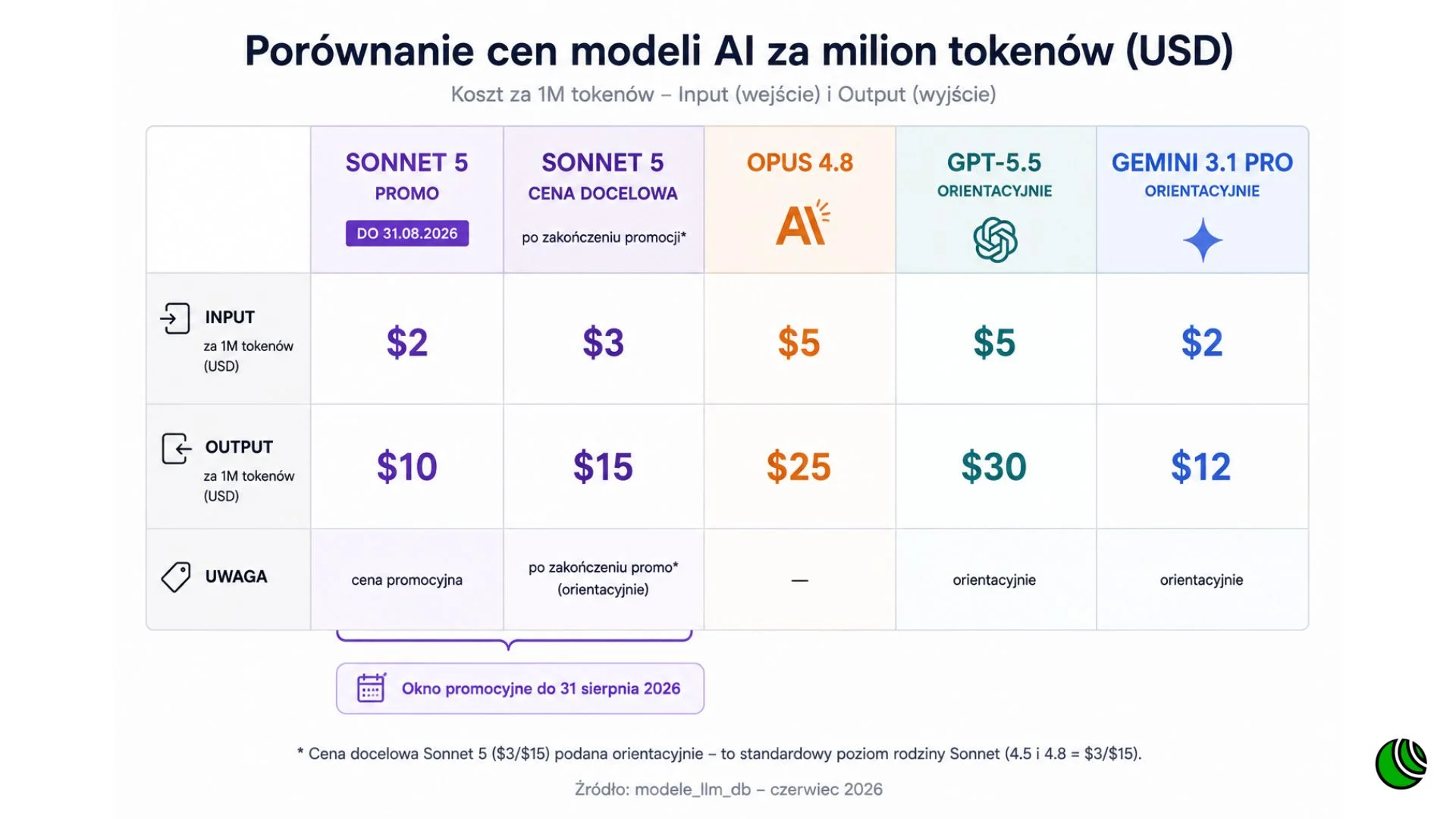
Promocyjna cena Claude Sonnet 5 na Claude Platform wynosi 2 dolary za milion tokenów wejściowych i 10 dolarów za milion tokenów wyjściowych, i obowiązuje do 31 sierpnia 2026 roku. Potem cena rośnie do 3 dolarów za input i 15 dolarów za output. Brzmi jak podwyżka o połowę, i formalnie nią jest, ale rzeczywisty obraz jest bardziej pokrętny.
Effort, czyli suwak myślenia, który podbija koszt
Sonnet 5 dostał pięć poziomów effortu: low, medium, high, nowy xhigh i max, dokładnie jak w Opus 4.8. Effort to suwak, który mówi modelowi, jak długo i jak dokładnie ma "myśleć" nad zadaniem, zanim odpowie. Wyższy poziom oznacza więcej wewnętrznych kroków rozumowania, a każdy taki krok to dodatkowe tokeny, więc wyższy rachunek.
Tu pojawia się ostrzeżenie, które warto zapamiętać przed liczeniem budżetu z góry. Według indeksu ArtificialAnalysis, przywoływanego w dyskusji na r/ClaudeAI, przy najwyższych poziomach effortu Sonnet 5 potrafi zużyć więcej tokenów na osiągnięcie tego samego wyniku niż droższy nominalnie Opus 4.8. Model tańszy na papierze wychodzi wtedy drożej w praktyce. Praktycy w tym wątku rekomendują trzymanie Sonnet 5 na poziomie medium do codziennej roboty i rezerwowanie wyższych poziomów wyłącznie na trudne, jednorazowe problemy, gdzie dokładność faktycznie się liczy.
Jak to wygląda na tle konkurencji
TechCrunch w swoim materiale porównującym ceny modeli wskazuje, że Sonnet 5 wypada taniej niż GPT-5.5 od OpenAI i Gemini 3.1 Pro od Google, ale wciąż drożej niż Gemini 3.5 Flash. To pokazuje, w którą stronę idzie ta gra: mniej o samą jakość odpowiedzi, coraz bardziej o koszt za tę samą jakość.
Sam na czas promocyjnego cennika przełączam swoje automaty scrapujące na Sonnet 5, dopóki jest taniej, sprawdzam go w realnej pracy zamiast wierzyć na słowo materiałom producenta. Właśnie dlatego przy budowaniu systemów warto od razu zakładać, że model pod spodem kiedyś się zmieni, i konstruować automatyzacje tak, żeby dało się je bezpiecznie przepiąć, gdy zmieni się cennik albo pojawi lepsza opcja.
Kiedy w ogóle nie musisz liczyć tokenów
Jeśli korzystasz z gotowych narzędzi typu Notion AI, cała ta arytmetyka z tokenami, tokenizerem i poziomami effortu w ogóle cię nie dotyczy. Wybór modelu z listy jest natychmiastowy, bez konfiguracji API i pilnowania cennika, bo Claude jako agent w Notion pokazuje, jak to wygląda od strony użytkownika końcowego, który po prostu klika model z listy zamiast liczyć koszty na poziomie API. Dla firmy bez działu technicznego to bywa wygodniejsze niż oszczędność kilku procent na cenniku, którą i tak trudno przeliczyć na realne złotówki bez śledzenia zużycia tokenów.
Dla kogo Claude Sonnet 5 robi realną różnicę, a kto tego nie odczuje
Skoro Sonnet 5 dogania Opus 4.8 pod względem jakości, Anthropic pisze wprost, że wynik zbliża się do droższego modelu przy wyraźnie niższej cenie, pytanie "dla kogo to ma sens" sprowadza się do jednego testu. Jeśli dotąd płaciłeś za Opusa, bo tylko on dawał wystarczającą jakość, Sonnet 5 może dać podobny efekt taniej. Jeśli nigdy nie sięgałeś po Opusa, bo Sonnet 4.6 wystarczał, ta zmiana cię nie dotyczy.
Kto odczuje różnicę: praca z dokumentami i researchem
Najwyraźniejsze przesunięcie widać w zespołach, które budują workflow prawne albo analizę dużej liczby dokumentów. Mauricio Wulfovich, Staff ML Engineer, opisuje to wprost w kontekście zadań researchu prawnego dla powodów: "Claude Sonnet 5 sits on the Pareto frontier for Eve's plaintiff-law tasks. We see the clearest gains in legal research and analysis, at a price-to-performance ratio that made the choice to migrate easy." Przełożone na prostszy język: model daje najlepszy stosunek jakości do ceny akurat tam, gdzie trzeba przekopać setki stron i wyciągnąć z nich sens, a nie tam, gdzie liczy się kreatywność czy błyskotliwa odpowiedź.
Drugą grupą, która realnie to poczuje, są firmy operujące na dużą skalę, obsługa klienta na tysiącach zgłoszeń, operacje masowe, gdzie liczy się nie pojedyncza odpowiedź, tylko przepustowość. Ben Kus, Chief Technology Officer, ujmuje to tak: "For enterprise teams managing high-volume, complex workloads, Claude Sonnet 5 represents a genuine step forward, strong performance where it counts, with the speed and cost profile that makes scaling practical." Innymi słowy: przy dużym wolumenie zapytań nawet niewielka poprawa szybkości i kosztu na jedno zapytanie mnoży się do konkretnych oszczędności.
Kto tego nie zauważy
Standardowa praca z raportami finansowymi, analizy biznesowe, podsumowania kwartalne, to obszar, w którym zespół Caylent w swoich testach nie zaobserwował znaczącej poprawy Sonnet 5 nad Sonnet 4.6 poza kodowaniem i narzędziami. Jeśli AI w firmie służy głównie do tego typu pracy z wiedzą, przełączenie modelu może nie dać niczego poza wyższym rachunkiem po sierpniu 2026.
Zvi Mowshowitz, autor bloga thezvi.substack.com, dorzuca ważne zastrzeżenie do całej dyskusji: Sonnet 5 to nie model "frontier", czyli nie przesuwa granicy tego, co AI w ogóle potrafi. To model, który poprawia stosunek szybkości, kosztu i jakości w istniejących ramach. Dla firmy nie liczy się, czy to najlepszy model na świecie, tylko czy rozwiązuje konkretny problem taniej albo szybciej niż to, czego już używasz.
Gdzie lepiej zostać przy droższym modelu
Jest jeden obszar, w którym Sonnet 5 wypada gorzej niż nazwa sugeruje. W opisie premiery Anthropic napisał, że Sonnet 5 ma niższy ogólny wskaźnik niepożądanych zachowań niż Sonnet 4.6, ale mniejszą zdolność do zadań cyberbezpieczeństwa niż obecne modele Opus. Dla firmy, która chciałaby użyć modelu do audytu bezpieczeństwa IT czy testów penetracyjnych, to sygnał, żeby zostać przy droższym Opusie, tu oszczędność na cenie może kosztować więcej w postaci przeoczonej luki.
Warto też rozszyfrować jeden termin, który pojawia się w materiałach źródłowych: sycophancy. To skłonność modelu do przytakiwania użytkownikowi zamiast powiedzieć mu wprost, że się myli. Sonnet 5 ma tego mniej niż poprzednik, co w praktyce oznacza, że jego odpowiedzi warto traktować jako bardziej wiarygodne, model rzadziej mówi ci to, co chcesz usłyszeć, zamiast tego, co jest prawdą.

Przełączać automaty na Sonnet 5, czy zostać przy starym modelu: co mówią pierwsze testy
Deklaracje producenta to jedno, a praca na żywym organizmie firmy to drugie. Dlatego zamiast wierzyć slajdom z premiery, warto zerknąć na to, co dzieje się, gdy ktoś faktycznie odpala Sonnet 5 przy konkretnym zadaniu, a nie na demo przygotowanym pod kamerę.
Test na żywo: ta sama gra, dwa różne podejścia
W teście opublikowanym na YouTube ktoś zlecił obu modelom identyczne zadanie: zbudować prostą grę od zera. Sonnet 5 zaczął działać niemal natychmiast, instalując zależności i pisząc kod bez długiego namysłu. Opus 4.8 najpierw dłużej "myślał" nad strategią, zanim ruszył do implementacji. Finalny efekt był porównywalny, ale rachunek już nie: Sonnet 5 zużył około 13 000 tokenów, Opus 4.8 około 9 800, czyli o jakieś 3 000 tokenów mniej za zbliżony rezultat. Tańszy model za pojedynczy token wcale nie musi znaczyć tańsze zadanie, to samo zastrzeżenie, które wcześniej pojawiło się przy wysokich poziomach effortu.
Code review studzi entuzjazm do pisania kodu
Recenzja CodeRabbit jest w tej kwestii jednoznaczna: do pisania nowego kodu Sonnet 5 to najbardziej zdolny model w tej warstwie cenowej, jaki tam testowali, czyli realny powód, żeby rozważyć zmianę. Przy code review obraz się komplikuje. Komentarze są czystsze i bardziej uporządkowane, ale model wychwytuje mniej błędów niż narzędzia dotąd używane produkcyjnie, a pojedyncze review wychodzi drożej. To nie wada dyskwalifikująca, tylko kompromis, o którym warto wiedzieć przed przełączeniem automatu odpowiedzialnego za kontrolę jakości kodu.
Szybkość ma cenę
Sonnet 5 potrafi być wolniejszy od Sonnet 4.6 przy drobnych, rutynowych poprawkach, bo dłużej "myśli" nad odpowiedzią, nawet tam, gdzie wystarczyłaby prosta reguła. Dla małego, powtarzalnego automatu, który ma wykonać jedną prostą czynność tysiąc razy dziennie, to może być bolesny tradeoff. Dla dużego, złożonego zadania ten sam dłuższy namysł zwykle się opłaca.
Warto też pamiętać, że nawet liczby od samego producenta bywają korygowane po fakcie. W changelogu premiery Anthropic doprecyzował, że benchmark BrowseComp dla Sonnet 5 liczono metodą z budżetem 10 milionów tokenów, z compaction i programistycznym wywoływaniem narzędzi, co zmieniło wynik względem pierwotnie opublikowanej wersji. Skoro oficjalny benchmark trzeba było poprawić, tym bardziej nie warto opierać decyzji o przełączeniu automatu wyłącznie na tabelkach z premiery, tylko na własnych danych.
Reddit: entuzjazm z nutą frustracji
Wątek premierowy na r/ClaudeAI zebrał 2728 upvote'ów, a dominujący ton jest pozytywny, choć nie bezkrytyczny. Społeczność rekomenduje wzorzec pracy "Opus planuje, Sonnet wykonuje" jako optymalny podział ról w agentowych workflow, a Sonnet 5 ten wzorzec wzmacnia, będąc przy tym wyraźnie mniej "gadatliwym" niż Opus 4.8. Frustracja w tym samym wątku nie dotyczy jednak jakości modelu, tylko braku resetu limitów użycia po premierze i wrażenia, że mniejszy model Haiku został przy okazji zaniedbany. To ważny kontekst całej premiery, nie wada samego Sonnet 5.
Osobny, praktyczny plus dla osób pracujących w Notion: Notion 3.6 ogłosił, że Claude i Cursor są pierwszymi dwoma External Agents dostępnymi w tej aplikacji. W Notion AI Sonnet 5 jest do wyboru od ręki, wystarczy wskazać model z listy, bez konfigurowania API i pilnowania cennika. Notion konsekwentnie dba o to, żeby najnowsze modele trafiały na listę wyboru niemal natychmiast po premierze.
Co z tego wynika dla Twojej firmy
Sonnet 5 to nie przełom, na jaki zapowiedzi premier chciałyby go wykreować. To wyraźny krok naprzód w konkretnych obszarach: agentowości, kodowaniu, pracy z narzędziami i bezpieczeństwie, przy niższej cenie niż droższy Opus 4.8. Warto jednak pamiętać, że promocyjne 2 dolary za milion tokenów wejściowych i 10 dolarów za wyjściowe obowiązują tylko do 31 sierpnia 2026. Potem cena rośnie do 3 i 15 dolarów, a nowy tokenizer sprawia, że te same zadania i tak wyjdą realnie droższe o jakieś 30%.
Największą różnicę odczują firmy z workflow prawnym, analitycznym na dużą skalę i zespoły puszczające agentów na wieloetapowe zadania. Standardowa praca z raportami czy analizami finansowymi zwykle niczego tu nie zyska. Lepiej przetestować go na jednym konkretnym automacie, budować systemy tak, żeby dało się łatwo przepiąć model, i decydować na podstawie własnych danych, nie samych tabelek z premiery.
Chcesz, żeby AI robiło u Ciebie realną robotę, a nie tylko błyszczało na demo? Napisz, przejdziemy przez Twoje dane i procesy i wskażemy jedno miejsce, gdzie AI od razu oszczędzi czas.
Czy Claude Sonnet 5 zastępuje droższy model Opus 4.8?
Nie całkowicie. Sonnet 5 zbliża się do jakości Opusa w wielu codziennych zadaniach, agentowej pracy, kodowaniu, obsłudze narzędzi, i robi to taniej. Ale w złożonym rozumowaniu bez wsparcia narzędzi oraz w zadaniach związanych z cyberbezpieczeństwem Opus 4.8 nadal wypada lepiej. Traktuj Sonnet 5 jako bardzo dobry środek, nie jako zamiennik jeden do jednego.
Czy warto czekać z decyzją do końca okresu promocyjnego?
Nie ma takiej potrzeby, wręcz przeciwnie. Cena promocyjna, 2 dolary za milion tokenów wejściowych i 10 dolarów za wyjściowe, obowiązuje do 31 sierpnia 2026. To najlepszy moment na testy, bo potem koszty wracają do poziomu docelowego 3 i 15 dolarów. Czekanie oznacza tylko mniej czasu na sprawdzenie modelu w tańszych warunkach.
Czy Sonnet 5 nadaje się do pracy z danymi wrażliwymi klientów?
Model ma poprawioną odporność na prompt injection, czyli próby przemycenia złośliwej instrukcji ukrytej w dokumencie, i mniej halucynacji niż poprzednik, co obniża ryzyko przy codziennej pracy z dokumentami klientów. Do zadań stricte związanych z bezpieczeństwem IT, audytów, testów penetracyjnych, Anthropic sam rekomenduje mocniejszy model Opus, więc tam lepiej nie oszczędzać.
Jak zacząć korzystać z Sonnet 5 bez konfigurowania API?
Najprościej przez narzędzia, które już go obsługują. W Notion AI model wybiera się z listy bez dodatkowej konfiguracji, Notion regularnie dodaje nowe modele od razu po premierze. Można też po prostu wejść na Claude.ai, gdzie Sonnet 5 jest domyślnym modelem w planach Free i Pro, więc część użytkowników korzysta z niego, nawet nie wiedząc o zmianie.
Czy trzeba przepinać wszystkie automaty na nowy model od razu?
Nie, i szczerze odradzam takie tempo. Bezpieczniej przełączyć jeden konkretny workflow, na przykład jeden automat scrapujący czy jeden proces obsługi zgłoszeń, przetestować go na własnych danych przez okres promocyjny, a dopiero potem decydować, czy zmiana ma sens na stałe w całej firmie. Hurtowe przepinanie wszystkiego naraz to prosta droga do niespodzianek w rachunku.
Zrodla
- Introducing Claude Sonnet 5 \ Anthropic
- Claude Sonnet 5 review: Should you switch? | CodeRabbit
- Claude Sonnet 5 review: is it the one to actually use? | eesel AI
- Claude Sonnet 5 Launch Analysis: What Changed, What Matters, and What to Validate | Caylent
- Claude Sonnet 5 Is Not Frontier But Has Its Uses | thezvi
- Anthropic launches Claude Sonnet 5 as a cheaper way to run agents | TechCrunch
- YouTube: test praktyczny Claude Sonnet 5 vs Opus 4.8
- Reddit: Introducing Claude Sonnet 5, our most agentic Sonnet yet
- Notion Releases 3.6